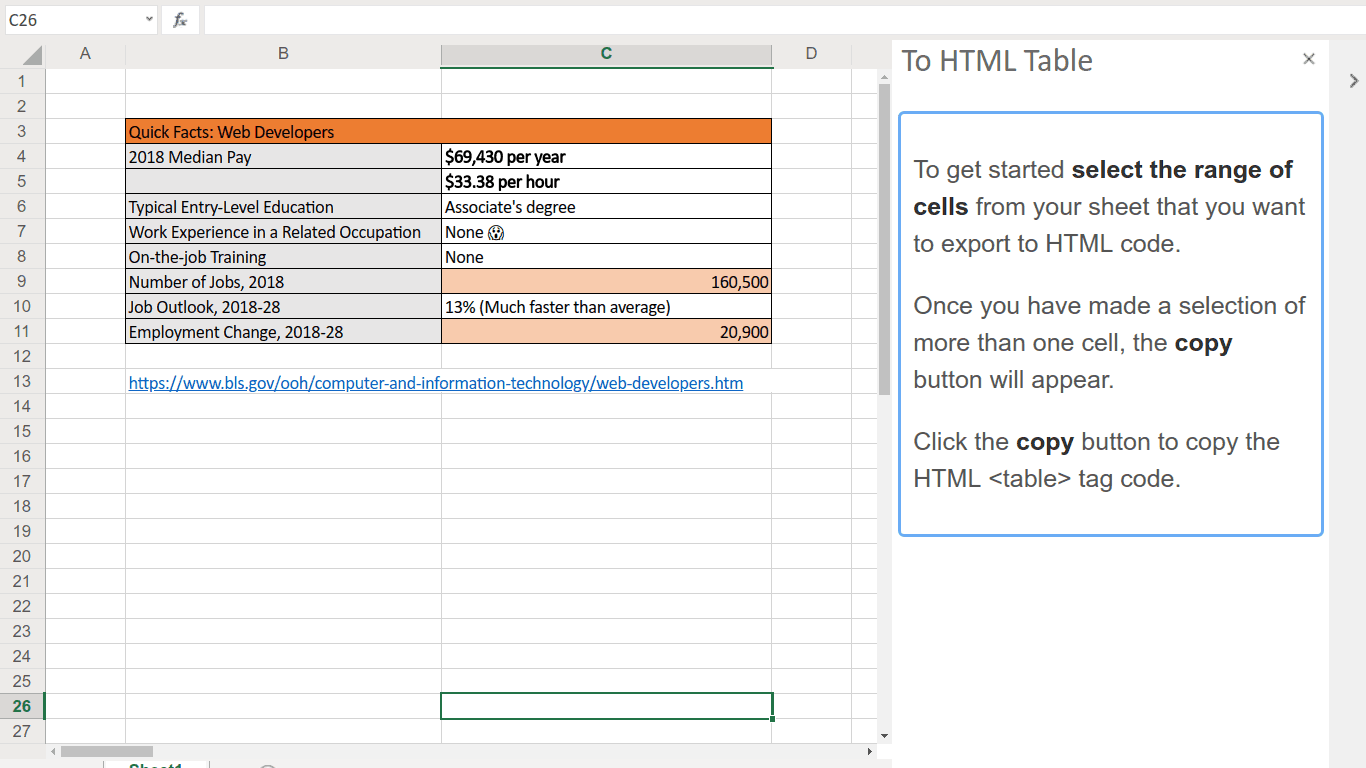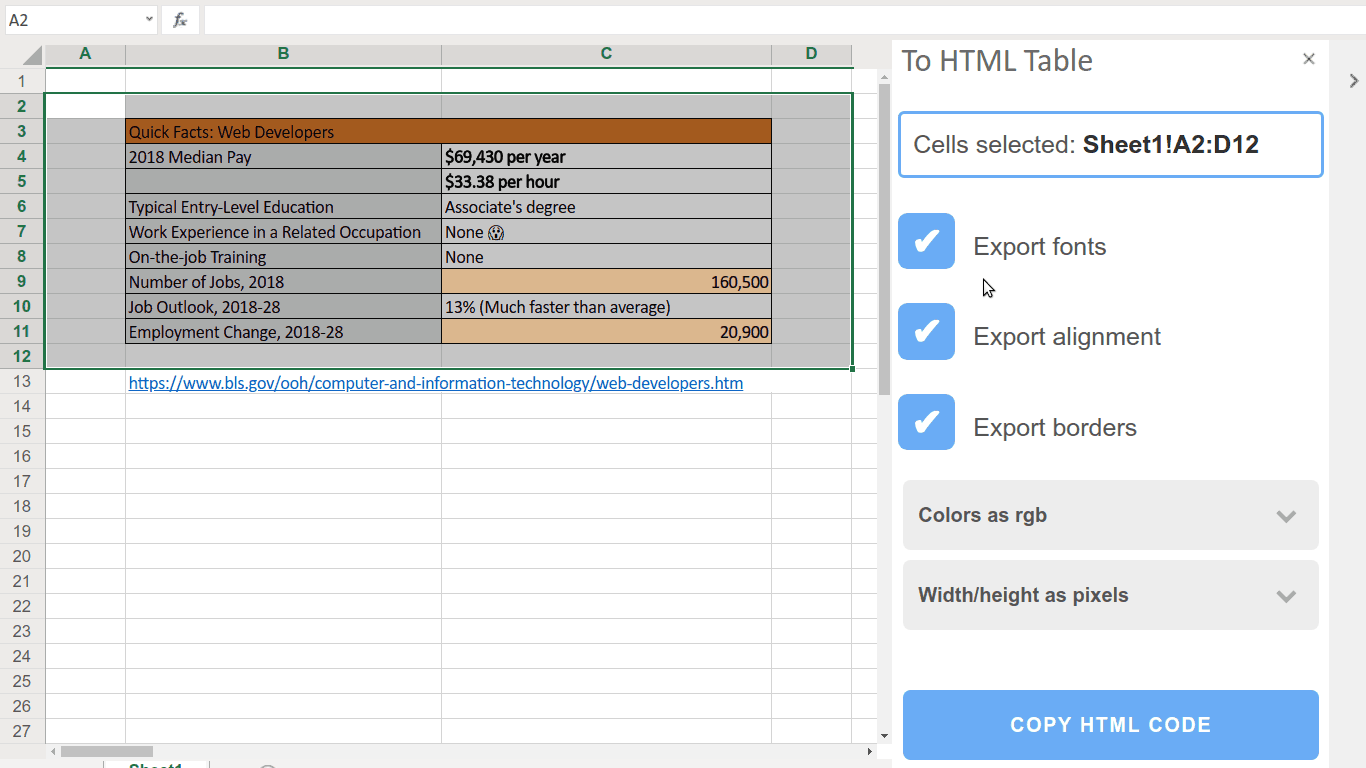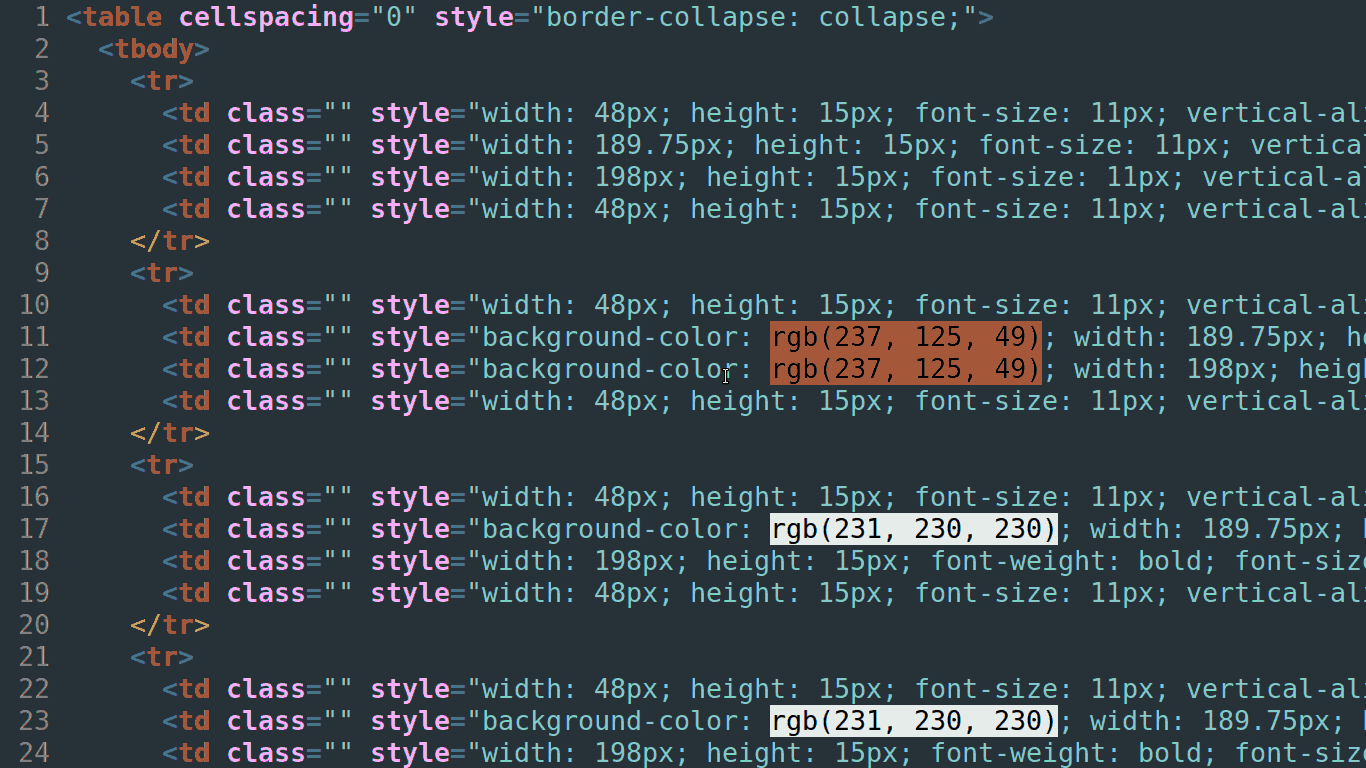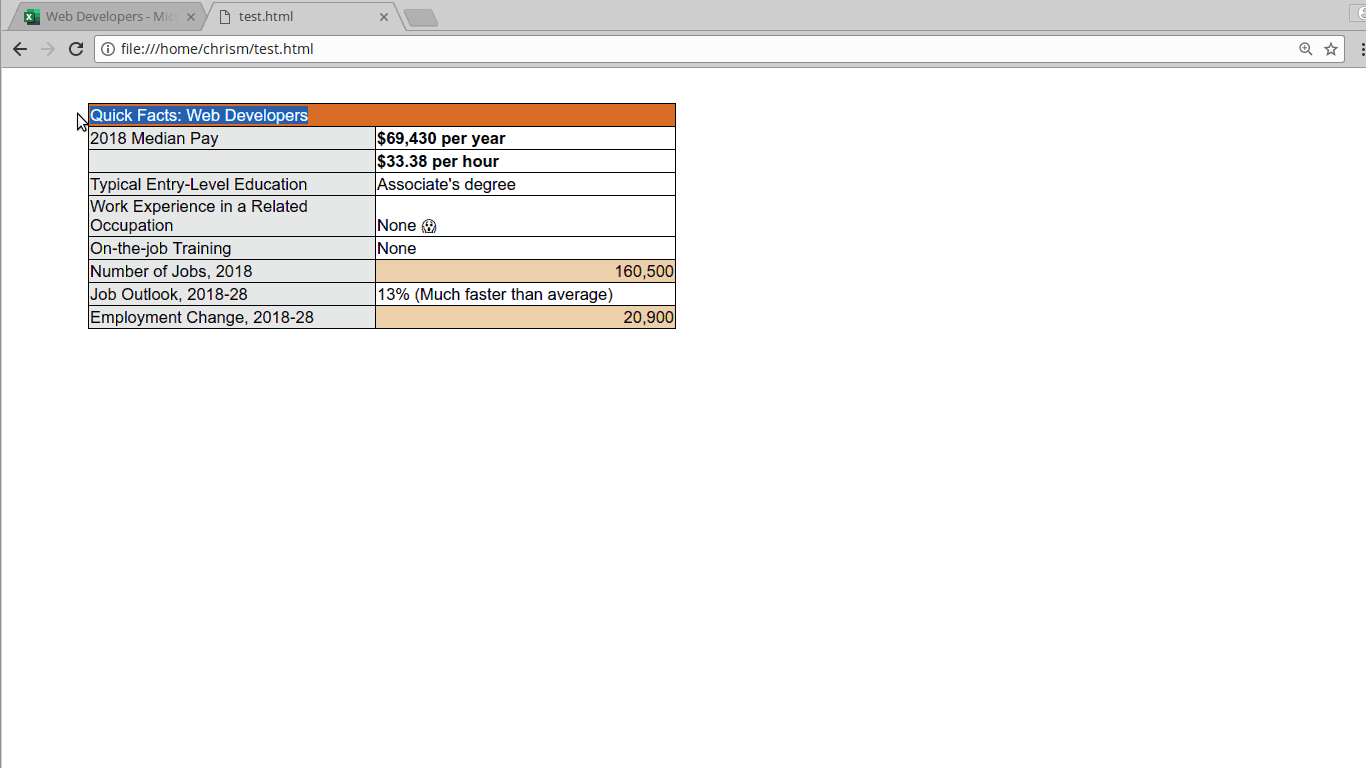
In 2014 Arvid Norberg and Steven Siloti came up with a BitTorrent extension called BEP44. The basic purpose of BEP44 is to allow people to store small pieces of information in a part of the BitTorrent network called the DHT. The DHT ("distributed hash table") is a key/value lookup table that is highly decentralized. Prior to BEP44 it was used to look up the IP addresses of peers from the hashes of the torrent they were sharing.
BEP44 introduces two new ways of storing key-value data in the DHT. The first is the ability to look up small bits of information keyed directly on their hash. The second allows for the storage of cryptographically authenticated data, keyed on the public key. What this means is if you have some public key K then you can look up authenticated blobs of data stored in the DHT by the owner of that key. This opens up a variety of useful abilities to people building decentralized applications.
For instance when you distribute a file on BitTorrent it is immutable - you can't change it - but BEP44 provides a way to tell people "hey, there is a new version of this file that I shared before which you can find over here" in a secure and authenticated way. It turns out that this basic mechanism can be used to build a wide variety of decentralized, authenticated functionality and people have built cool experiements like a decentralized microblog using it.
The purpose of this post is to show you how the datastructure works and how to apply it more widely in your own software.
If you just want a working implementation you can use, check out the decentral-utils JavaScript library which has a single-function implementation of the datastructure and algorithm which you can use in the browser. Web browsers unfortunately do not have direct access to the BitTorrent DHT, but the library is still useful for authenticating up-to-date data blobs that are passed around between browsers, for example over WebRTC.
What's good about BEP44
Most of the advantage of BEP44 comes from the cryptographic signing. What this offers is a way for somebody (let's call her Alice) to verify that a piece of data from somebody else (let's call him Bob) is authentic and that it has not been tampered with. You can do cryptographic signing without BEP44 of course.
However, the BEP44 specification brings some other features for building decentralized systems:
- Namespacing against a public key.
- Replay attack prevention.
- A compare-and-swap primitive.
The namespacing feature means that a single public key can have a bunch of different data blobs that others can authenticate. Because the datastructure is keyed on both the public key and a "salt" field, a single public key can store multiple blobs with different "salt" values as a sub-key.
Replay attack prevention is accomplished with the sequence field, which in BEP44 is a monotonically increasing integer. The way a replay attack works is some adversary keeps an old copy of something you have signed and then when you are offline they send it again and pretend its a new message. Because the message is signed with your key people are fooled by the adversary into thinking the old data is current. In BEP44 the sequence field prevents this because the adversary will have a data blob with a lower sequence number than the last one you shared and they can't generate a new blob with a higher sequence number because they do not have your private key. So the replayed data blob will be rejected.
Finally, the compare-and-swap primitive works by specifying a previous sequence number that the current data blob should replace. Peers will reject data blobs which don't replace the current sequence number they hold. In this way it's possible to acheive basic synchronisation and atomicity of data blobs. Using compare-and-swap guarantees that the new value you want to insert into the DHT can be calculated based on up-to-date information.
Example usage
Imagine you take upon yourself the small task of building a decentralized social network. Users have a timeline of posts which they have written. When they write a new post it should be appended to their timeline and people should see the updated timeline with the new post.
In the centralized social network case this is easy. The social network provider TwitFace has an internal copy of the poster's timeline to which they add the new post. Followers are notified of the update and the updated timeline is sent to them by the provider. The way the authentication works in this case is the original poster has logged in with their password and so the provider knows who they are, but the receivers of the update must trust the provider.

How do readers know that the post is authentic and comes from the original poster? The reader must trust the provider completely. They must trust that the provider is showing them the authentic timeline of messages, that the messages have not been modified, that fake messages have not been injected into the timeline, that new messages have been added to the feed in a timely fashion, and that no message has been censored and removed from the feed by the provider.
The problem with this model is that trusted third parties are security holes. Centralized social networks do modify things people have said. They do inject posts into people's timelines (ads and worse). They do change the order and timing of posts to suit their own goals. Perhaps worst of all, they do censor posts completely.
I won't get into the politics of censorship. Suffice it to say that censorship is fine and good right up until the point where your values differ from the entity doing the censoring. Values change, mysterious outside influences are myriad, and few people have complete alignment of values even with our noble corporate overlords in Silicon Valley.
The basic goal here is that if you've chosen to read somebody's timeline you can trust that the feed of posts you are reading from them is authentic and complete and as they intended.
Happily, we can use the BEP44 technique to route around the trusted-third-party centralized-social-network-provider security hole. BEP44 provides a way to receive an update and verify it cryptographically. It provides a way to know that this is the latest and complete version. It allows the verifier to do this using only the received data structure without requiring any kind of secret server side logic or password based authentiction like you would find in a centralized social network.

How it works
At the heart of the algorithm is a small datastructure which can be shared, updated by the sharer, and then shared again. Receivers can verify the updates are authentic. The idea is that you can share a small piece of authenticated data which points to a larger piece of immutable data. For instance, you can share an authenticated datastructure with the hash of a torrent containing all of your posts (an RSS feed for instance). Receivers then know that torrent is the current representation of your timeline of posts.
The datastructure has the following fields:
- value
- seq
- cas [optiona]
- salt [optional]
- pubkey
- signature
When a verifier receives a copy of this data structure they perform the following checks:
- Is the size of the
valuefield below the maximum size? - Does the
valueconform to the expected format / encoding? - Is the
seqnumber higher than the lastseqnumber I saw (if any)? - If
casis present does it match the previousseqnumber I have? - Is the attached signature made with the private key corresponding to the attached pubkey over the datastructure's value, seq, and salt fields?
In this final point they are checking that the structure has been digitally signed with the author's private key. This is accomplished by concatenating salt + seq + value and then checking that the signature is valid for that data and the given public key.
In this way verifiers can know that an update from a known keypair/identity is authentic and current.
Read more posts on the subject of cryptography & decentralized systems.